I usually put FS2 amongst my top favourite libraries in my career. This streaming library powers some of the most popular Scala Typelevel libraries. I often encounter streaming design problems that make me think to myself, “you can do this with a couple lines of FS2”. Enough gushing. I typically find that folks who come across FS2 struggle with creating a correct mental model for how a stream in FS2 works.
This article assumes you know about Cats-Effect and FS2 already and would like to dive deeper. Understanding how FS2 works requires a mental model for how suspended side effects work too.
On the surface, an FS2 Stream looks and feels a lot like a collection (like List). It supports common collections
operations like map, flatMap, or filter. In fact, when we go to complete a stream, we can convert our stream to a
host of different collection types.
| |
This property of Streams makes it easy to understand the API at first, but can make it difficult to understand how it
works internally. A Stream differs from a List in that it incorporates an effect type (F[_]) as part of its
definition (Stream[F, A]). So why do we need an effect type for our stream definition? A Stream does not necesserily
hold all elements in memory at once. For example, if we stream an HTTP response, not all body bytes arrive from the
network at the same time.
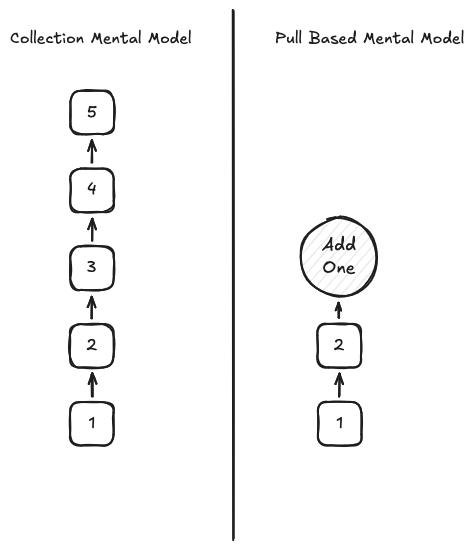
When using an effectful type (like IO), a Stream[IO, A] actually represents a single IO[Option[A]] that we call
repeatedly for new results. We refer to this as a “pull-based” stream because we need to perform an action to retrieve
the next elements of the stream. This works the same as Scala’s Iterator class when lazy generating results. As this
diagram shows, we don’t materialise the elements of the Stream until we reach them.
Another important thing to note about Streams; they don’t (always) contain single elements. Instead, they contain
multiple groups of elements (Chunks), which allows individual pulls to return more than one element. Useful when
working with things like response payloads where consuming bodies byte by byte could harm performance. At one time a
Stream only holds a single chunk. It pulls a new chunk as necessary when we consume the stream.
Pull API
Armed with this understanding of how a Stream works we can actually access the underlying representation type,
Pull. Given an arbitrary stream we can call .pull to convert a Stream into a Pull. This type covers some
internal implementation details but, in a nutshell, a Pull monad represents a single “step” of the underlying
representation. For example, a single Pull might represent polling a connection for new response bytes.
Technically .pull returns a ToPull type. Again, this type covers some internal implementation details but acts as a
springboard for calls like uncons or peek, which can optionally consume the current chunk. Operations on this type
always yield a Pull so for our purposes I will focus on that.
A Pull type can cause confusion because it has three type parameters.
| |
The effect type simply represents the monad in use (e.g. IO). The output type represents the type of the parent
Stream. The return type represents a “working” type to allow use to compose multiple Pulls into a single stream
step. We can only collapse Pulls back to a normal Stream if they return a Unit type (signalling they are
“done”), using the Pull.stream API. This distinction can make Pull a confusing type to work with at first.
| |
Pull.output1 emits the given value as an element in our stream. Pull.done just represents a Pull[F, Nothing, Unit]
and acts as a convenient way of signalling the current pull has finished outputting any elements.
You can define custom steps on an existing Stream by using .repeatPull. This gives you a high degree of control over
when and how we pull elements from the upstream. This function provides a base ToPull and asks you to return an
Option[Stream[F, A]] to indicate if and how the stream should continue. An interesting property of this stage is that
we don’t have to return elements from our upstream definition. We can insert new elements or switch to a different
stream entirely.
Motivation and Summary
FS2’s Stream already provides a lot of powerful abstractions for working on a stream without dipping into the pull
API, so why might you want to?
Performant consumption of chunks. Individually stream operations can provide either full chunks (via
.chunks) or single elements. If you ever want to combine elements across chunks or dynamically merge chunks then you will need to pull and merge chunks yourself.Single step logic. Sometimes you might want to partially consume a stream before making a decision on how to process the full stream. The pull API allows you to arbitrarily consume the Stream without committing to a single strategy.
Full control over execution. You might have a sensitive upstream API where you want to carefully choose when and how effects get executed.
Understanding how a Stream works underneath can help you intuit what a stream can (and can’t) do, as well as
diagnosing any performance issues. The pull API unlocks performance improvements around chunk handling that the
typical Stream interface might not provide. This might seem like a dense topic at first, but sometimes the best way
to learn something means using it. Then you should find the concepts click into place (and if they don’t, I
apologise unreservedly).